來源:北大青鳥總部 2023年06月27日 09:19
2020年天貓雙十一全球狂歡季成交額4982億元人民幣。在那年的整個雙十一中,我們通過Dashboard實時數據大盤可以知道每分鐘的成交額、訂單數、爆款商品、爆款售賣地區等等,這個Dashboard背后的技術便是數據實時計算和流式計算。
所謂實時計算指的是實時可以獲取到想要的數據,比如我想查詢我今年雙十一的購買額,輸入姓名、時間后立即可以統計出數據,所謂流式計算指的是我每買一件東西,購買量自動加1,訂單額自動增加。實時計算和流式計算都是相對離線計算的改善,離線計算有一定的延遲,它把數據從存儲中取出來,進行統計,最后再呈現。
我們在雙十一成交額大盤所看到的便是實時計算與流式計算的結合,實現流式計算的技術有很多,比如storm、spark、flink,而這其中最流行、使用最廣的便是flink,接下來我們就一起來看看flink到底是什么技術?

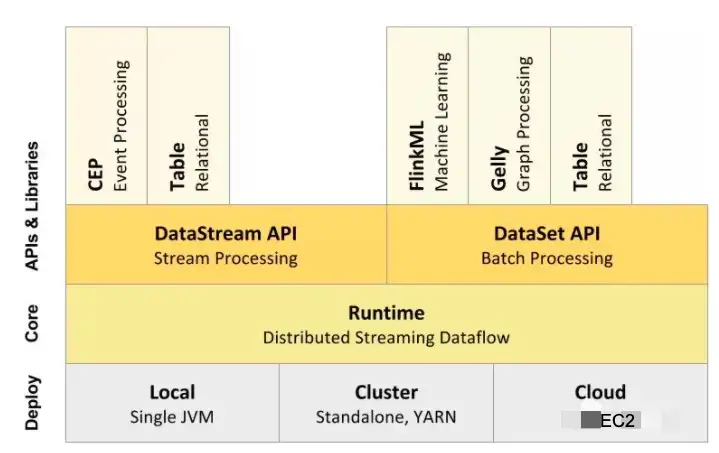
Flink是一個針對流數據、批數據進行處理的分布式處理引擎,可以處理有界限的數據(數據量有限,不會改變的數據集合,比如雙十一當天數據量)、無界限的數據(比如淘寶用戶產生的實時交互數據、股票市場的實時交易記錄)。在Flink的架構中包含四層,分別是Deploy部署層、Core核心層、API接口層、Lib擴展庫層。
在部署層主要是Flink的部署模式,它支持Local本地化部署,直接在IDE代碼編輯器中就可以運行程序;也支持集群化部署,在Kubernetes或使用Hadoop的Yarn來做集群調度;也支持云上部署,通過彈性主機實現自動擴縮容。在Core核心層,主要是分布式流式處理引擎,支持分布式stream處理,支持jobgraph到execution的映射調度,支持上層API接口的任務。在API層主要是提供API給到開發者編寫分布式任務,包含DataSetAPI、DataStreamAPI兩類API,DataStreamAPI主要用于對流數據進行處理,它可以將流式數據抽象成分布式的數據流,開發者就很方便的對分布式數據流進行操作處理,DataSetAPI主要對于數據進行批量處理,將靜態的、有限的數據抽象成分布式的數據集處理。在Lib擴展庫層主要是通過擴展庫方式提供更多使用場景給到開發者,比如CEP復雜事件處理、Table把結構化數據抽象成關系表,并支持類SQL語句查詢、FlinkML支持機器學習、Gelly圖計算庫支持圖處理。
了解完Flink的基礎框架之后,我們再來看看Flink的基本編程模型是怎么樣的?在Flink中主要是三個步驟,數據源進行數據輸入、數據轉換、數據輸出,開發者可以把數據庫的數據或自己本地文件數據或消息隊列Kafka的數據通過API接口傳遞給到Flink,Flink處理引擎將數據轉化成按時間窗口排序或按最熱門排序或按地區聚合等數據,最后再通過Sink將數據輸出到消息隊列或數據大盤中進行展示。

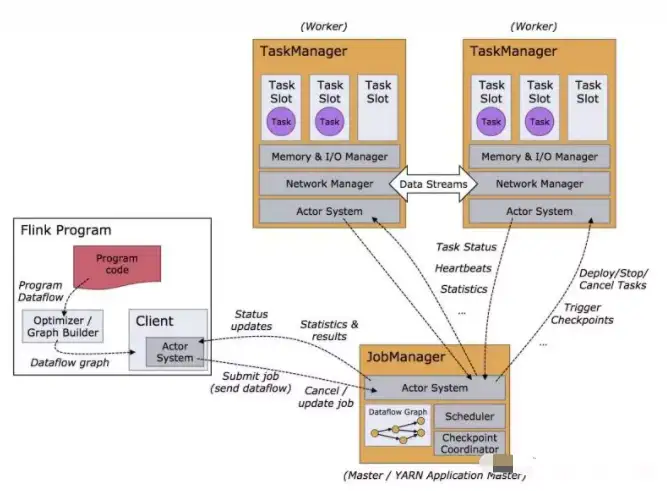
在Flink的處理引擎中,數據是這樣進行流轉,開發者編寫Flink應用程序代碼,通過Client傳遞給到JobManager,JobManager是Flink的Master節點,負責安排任務給到TaskManager去執行,同時管理TaskManager節點的調度情況,如果忙不過來或者故障,再把任務分配給到其它的TaskManager。TaskManager主要負責接收來自JobManager的任務,一個TaskManager占據一個JVM內存,在TaskManager中還包含TaskSlot的概念,用于內存分配管理,一個Slot代表為其分配100%的內存空間,兩個則代表為每個分配50%的空間,每個Slot占據1個線程來具體的執行任務。
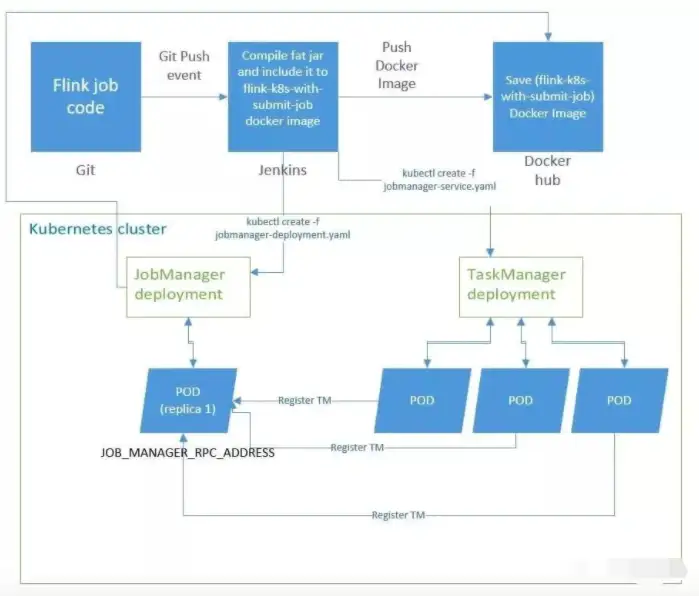
在DevOps工程師文化、Kubernetes容器技術盛行的互聯網,Flink也可以聯同二者進行工作,尤其是在大廠,基本都是這樣的架構運行原理。開發人員編寫好Flink任務代碼,通過Git的push事件進行代碼提交,同時觸發了對應的Jenkins集群,在Kubernetes中進行JobManager、TaskManager的部署,JobManager和TaskManager占據一個或多個POD,實現了自動彈性伸縮,開發者或運維人員基于Kubernetes還可以調度管理Flink系統。
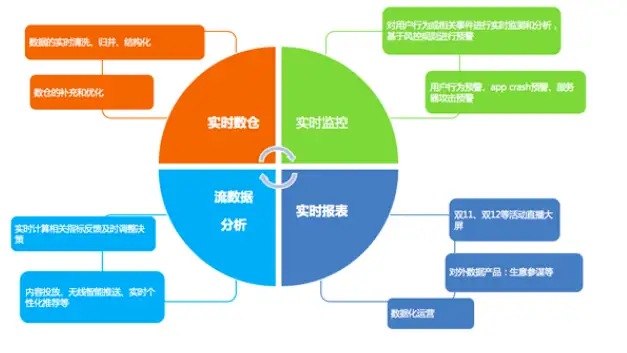
本文介紹了Flink的基本架構、編程模型、運行原理,它還有很多應用場景。我們抽象的從三個維度來看:
1、基于事件驅動,開發者將采集的事件不斷放入消息隊列,Flink不斷的進行消息隊列數據消費,每消費一條數據,則觸發一個動作,在欺詐檢測、異常檢測、基于規則的告警、業務流程監控中都可以使用Flink的這個特性;
2、分析場景,開發者將數據實時或周期性的寫入消息隊列,Flink不斷的將應用源數據做實時計算,不斷更新數據庫或HDFS,最后做大屏展示或數據報表,比如雙十一的DashBoard;
3、管道式ETL,即提取數據放到數據庫或文件系統當中。下圖是Flink在阿里巴巴內部的主要應用場景。
除了阿里之外,在百度、騰訊、美團、滴滴、頭條、京東、拼多多等公司,Flink的應用也是非常普及的。在互聯網流量為王時代,基于大數據去做離線分析、實時分析是必不可少的,數據開發工程師的薪酬也非常可人,掌握Flink基礎使用知識也是必備技能,如果你對大數據開發感興趣,那么趕快學習上車Flink吧~



 手機端官網
手機端官網

 京公網安備 11010802020714號
京公網安備 11010802020714號