來源:北大青鳥總部 2022年12月20日 14:32
最近小編已經將大數據系統的學習了一遍,對各個技術點已經了解清楚了,于是開始翻起了招聘網站,開始試水招聘市場。畢竟豬肉都漲價啦,小編學習了半年多的大數據沒理由身價還不漲。

瀏覽各公司招聘需求的過程中,相應的技術點要求小編倒是明白,雖然說不上精通,但是已經足夠的了解,并且也知其原理,看上去都十分的匹配,于是小編寫好簡歷之后迅速開始了投遞,接下來就是翹著二郎腿在家坐等面試。

投遞100篇簡歷的第1天,小編腦子里滿腦都是迎娶白富美的場景。

投遞100篇簡歷的第2天,小編自信依然,腦子里滿是offer收割現場。

投遞100篇簡歷的第12天,這沒道理呀,理論知識如此豐富的小編能不被相中?

投遞100篇簡歷的第20天,小編一邊吃著泡面,一邊給拒絕自己的HR厚著臉皮打去了電話。而大多數的對話如下:
“HR您好,我的理論知識豐富,我被刷下來的原因肯定是您沒看見,認真看一下?”“您好,您的簡歷我們技術部分負責人很認真看過,主要是因為您缺乏真實場景的項目開發經歷”
一語點醒夢中人,難怪小編投的簡歷都石沉大海,可是真實場景的大數據項目依賴著大量真實的數據,這是我們自學的人很難擁有的資源,就算是網上有許多教程,但是真實的業務數據也不可能會進行提供。

這個問題一直在困擾著小編,直到小編找到了一個神奇的庫——Python-faker
這個庫可不是打英雄聯盟那哥們兒開發的。它是一個專注于模擬生成數據的庫,并且它的簡單易用以及模擬數據的友好,完全可以將它生成的數據模擬出真實的業務場景。下面我們來具體介紹一下。
首先安裝faker庫,使用命令:pip install faker
安裝完成以后,就可以自由的使用faker庫了,使用的步驟非常簡單
導入faker庫:from faker import Faker
實例化Faker(),并傳入使用中文的參數:fake = Faker('zh_CN'),這樣生成的數據將是中文。
接下來就可以看看它造的數據了:
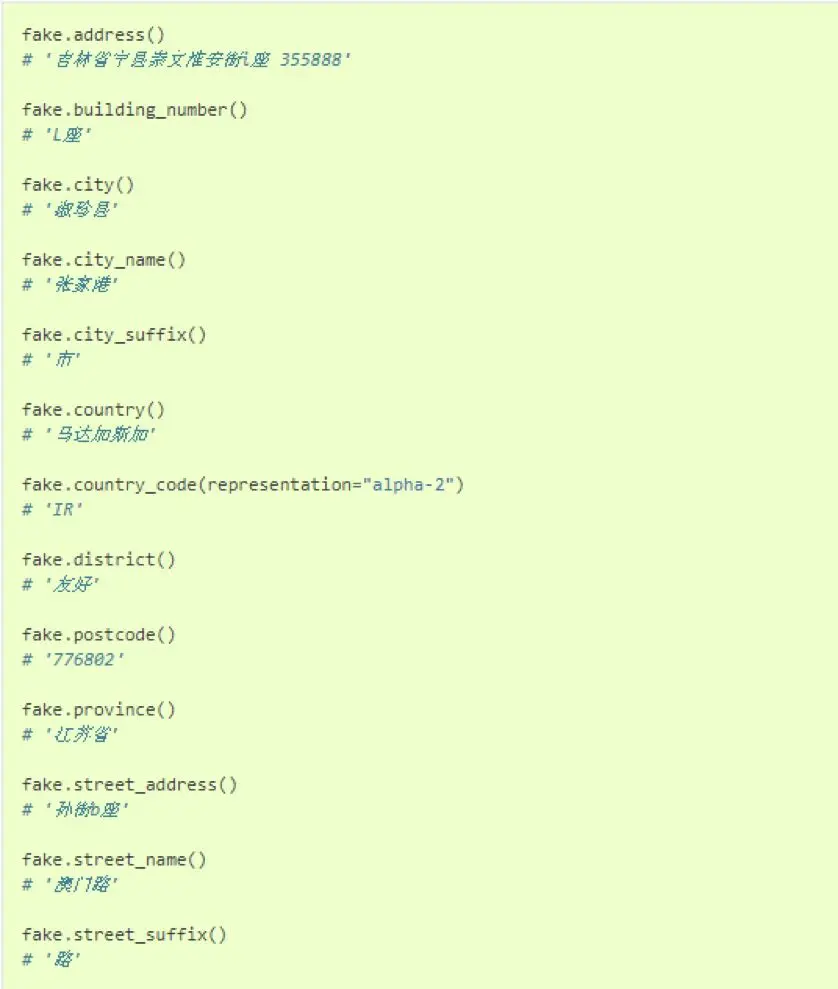
就是這樣簡單調用一下相關的api,它就可以給我們返回許多模擬的數據,當然你每次調用同樣的方法返回的結果都是不一樣的,因為它會隨機的生成模擬數據。這實在是太方便了吧,那除了以上這些api,它還提供了許多其他的api和方法來模擬生成相關數據。

來自官方文檔
https://faker.readthedocs.io/en/master/locales/zh_CN.html
它可以輕松模擬個人的各種信息:姓名、年齡、手機號、地址、地理坐標、銀行卡號、公司、工作類型等等等等。還能模擬爬蟲中經常使用的user-agent,還可以整段文本內容、日期,甚至一鍵生成個人簡介。

更多的模擬數據可以輕松訪問其官網進行查詢,有了這個庫以后,小編再也不擔心真實場景下的大數據開發經驗了。先用它模擬100條個人信息,然后再用它模擬一些購物行為數據,用于做購物網站的數據分析,或者購物網站推薦系統的數據源都可以。
有了這個庫,真實場景下的大數據開發經驗根本就沒問題了。先不說了,小編要開始模擬數據進行開發了,期待半個月后找到好的工作!
Faker庫官方文檔:https://faker.readthedocs.io/en



 手機端官網
手機端官網

 京公網安備 11010802020714號
京公網安備 11010802020714號